scatter_selector widget¶
A set of custom matplotlib widgets that allow you to select points on a scatter plot as use that as input to other interactive plots. There are three variants that differ only in what they pass to their callbacks:
scatter_selector: callbacks will receiveindex, (x, y)whereindexis the position of the point in the of the points.scatter_selector_values: callbacks will receivex, yscatter_selector_index: callbacks will receiveindex
In this example we will use scatter_selector_index along with the indexer convenience function to make line plots of stock data. However, you can use custom functions for the interactive plots, or even attach your own callbacks to the scatter_selector widgets.
PCA of Stock Data¶
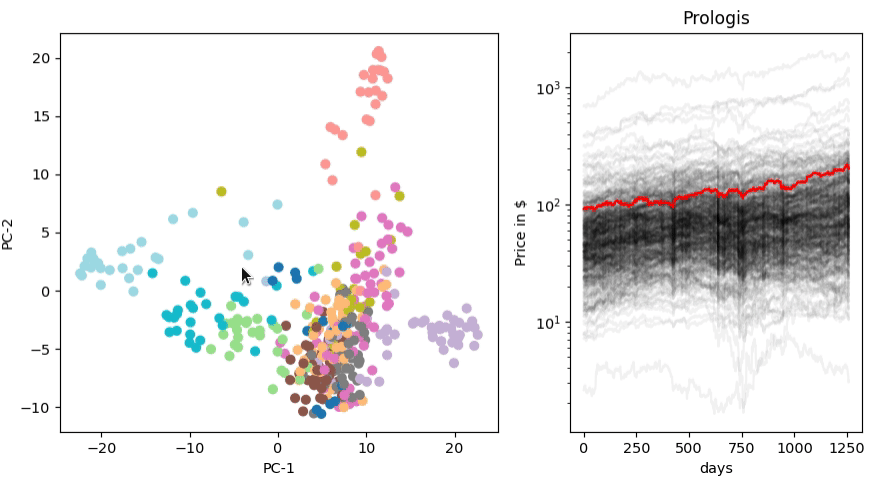
For this example we will plot companies in SP500 in a scatter plot by principle components extracted from principal components analysis (PCA) an interactive visualization of companies in SP500 using PCA. The data was originally obtained from https://www.kaggle.com/camnugent/sandp500 and the data was cleaned using code derived from https://github.com/Hekstra-Lab/scientific-python-bootcamp/tree/master/day3
[ ]:
%matplotlib ipympl
import pickle
import ipywidgets as widgets
import matplotlib.pyplot as plt
import numpy as np
import mpl_interactions.ipyplot as iplt
from mpl_interactions import indexer, panhandler, zoom_factory
from mpl_interactions.utils import indexer
from mpl_interactions.widgets import scatter_selector_index
Data loading/cleaning¶
For this example we have pre-cleaned data that we will just load. If you are curious on how the data was originally processed you see the full code at the bottom of this notebook.
The datafiles that we load for this example are available for download at https://github.com/ianhi/mpl-interactions/tree/master/examples/data
[ ]:
import pickle
with open("data/stock-metadata.pickle", "rb") as f:
meta = pickle.load(f)
prices = np.load("data/stock-prices.npz")["prices"]
names = meta["names"]
good_idx = meta[
"good_idx"
] # only plot the ones for which we were able to parse sector info
data_colors = meta["data_colors"]
# calculate the daily price difference
price_changes = np.diff(prices)
# Below is a pretty standard way of normalizing numerical data
normalized_price_changes = price_changes - price_changes.mean(axis=-1, keepdims=True)
normalized_price_changes /= price_changes.std(axis=-1, keepdims=True)
# calculate the covariance matrix
covariance = np.cov(normalized_price_changes.T)
# Calculate the eigenvectors (i.e. the principle components)
evals, evecs = np.linalg.eig(covariance)
evecs = np.real(evecs)
# project the companies onto the principle components
transformed = normalized_price_changes @ evecs
# take only the first two components for plotting
# we also take only the subset of companies for which it was easy to extract a sector and a name
x, y = transformed[good_idx][:, 0], transformed[good_idx][:, 1]
Making the plot¶
We create the left scatter plot using the scatter_selector_index which will tell use the index of the company that was clicked on. Since this is just a Matplotlib AxesWidget it can be passed directly to iplt.plot as a kwarg and the controls object will handle it approriately.
In this example we also make use of the function mpl_interactions.utils.indexer. This is a convenience function that handles indexing an array for you. So these two statements are equivalent:
# set up data
arr = np.random.randn(4,100).cumsum(-1)
def f(idx):
return arr[idx]
iplt.plot(f, idx=np.arange(4))
# or equivalently
iplt.plot(indexer(arr), idx=np.arange(4))
[ ]:
fig, axs = plt.subplots(1, 2, figsize=(10, 5), gridspec_kw={"width_ratios": [1.5, 1]})
index = scatter_selector_index(axs[0], x, y, c=data_colors, cmap="tab20")
# plot all the stock traces in light gray
plt.plot(prices.T, color="k", alpha=0.05)
# add interactive components to the subplot on the right
# note the use of indexer
controls = iplt.plot(indexer(prices), idx=index, color="r")
iplt.title(indexer(names), controls=controls["idx"])
# styling + zooming
axs[0].set_xlabel("PC-1")
axs[0].set_ylabel("PC-2")
axs[1].set_xlabel("days")
axs[1].set_ylabel("Price in $")
axs[1].set_yscale("log")
cid = zoom_factory(axs[0])
ph = panhandler(fig)
Datacleaning¶
Below is the code we used to clean and save the datasets. While we start out with 500 companies we end up with only 468 as some of them we were unable to easily and correctly parse so they were thrown away.
[ ]:
# NBVAL_SKIP
# Download the data from https://www.kaggle.com/camnugent/sandp500
# and save it into a folder named `data`
import glob
test = np.loadtxt("data/A_data.csv", delimiter=",", skiprows=1, usecols=1)
sp500_glob = glob.glob(
"data/*.csv",
)
names = []
prices = np.zeros((len(sp500_glob), test.shape[0]))
prices_good = []
fails = []
for i, f in enumerate(sp500_glob):
fname = f.split("/")[-1]
names.append(fname.split("_")[0])
try:
prices[i] = np.loadtxt(f, delimiter=",", skiprows=1, usecols=1)
prices_good.append(True)
except:
fails.append(fname.split("_")[0])
prices_good.append(False)
pass
prices = prices[prices_good]
np.savez_compressed("data/stock-prices.npz", prices=prices)
# processing names and sector info
arr = np.loadtxt(
"data/SP500_names.csv", delimiter="|", skiprows=1, dtype=str, encoding="utf-8"
)
name_dict = {a[0].strip(): a[[1, 2, 3]] for a in arr}
# idx_to_info = {i:name_dict[real_names[i]] for i in range(468)}
good_names = []
primary = []
secondary = []
good_idx = np.zeros(real_names.shape[0], dtype=bool)
for i, name in enumerate(real_names):
try:
info = name_dict[name]
good_idx[i] = True
good_names.append(info[0])
primary.append(info[1])
secondary.append(info[2])
except:
pass
psector_dict = {val: i for i, val in enumerate(np.unique(primary))}
data_colors = np.array([psector_dict[val] for val in primary], dtype=int)
import pickle
meta = {
"good_idx": good_idx,
"names": good_names,
"sector": psector_dict,
"data_colors": data_colors,
}
with open("data/stock-metadata.pickle", "wb") as outfile:
pickle.dump(meta, outfile)